



-

Analyst's Choice
Cyber Intelligence
フィッシング
GmailとMS 365の利用者は注意を:フィッシングキット「Tycoon 2FA」の概要と対策

Rory
2024.04.16
-

Analyst's Choice
AI
Cyber Intelligence
OSINT
DarkGPT – ChatGPT-4を活用した、流出データベース検出のためのOSINTツール
Rory
2024.04.15
-

Analyst's Choice
Cyber Intelligence
GitHub
Intelligence
脅威アクターがGitHubを不正な目的で悪用するケースが増加
Rory
2024.02.07



世界各地で発生するサイバー犯罪関連のニュースが飛び交う中、日本でもセキュリティに対する社会全体の意識が確実に高まってきました。さまざまな情報を収集・分析した知見を意味する「インテリジェンス」という言葉も、一部の専門家だけが使う特殊な用語ではなくなっています。
日々進化する脅威に対して先手を打つには、守る側でも新しいテクノロジーや戦略、フレームワークを採用し、これまで以上に効率的なセキュリティ体制を構築する必要があります。その強力な武器の1つとされているのが「インテリジェンスサイクル」です。
本記事では、インテリジェンスを継続的に収集、分析、活用、評価し、改善につなげるこのプロセスの概要を説明すると共に、要件定義や情報収集、分析から配布までの流れをわかりやすく解説します。
目次
[開く][閉じる]- 情報とインテリジェンス
- 主な実施内容
- 検討すべきポイント
- 3種類のサイバーインテリジェンス
- 要件定義について
- データソースの決定
- 検討すべきポイント
- 主な実施内容
- 分析の例
- 成果物の作成
- 主な実施内容
- 検討すべきポイント
- 主な実施内容
- 検討すべきポイント
- インテリジェンスの取り組みを行うための基本指針となる
- 構造的・体系的なアプローチが可能になる
そもそもサイバーインテリジェンスとは?
情報とインテリジェンス
情報セキュリティ関連の脅威に関するすべての情報のうち、脅威に対する自衛、あるいはアクターの活動を検知するために役立つ可能性があるものを「脅威情報」といいます。サイバー攻撃の痕跡情報(indicator)、攻撃者の戦術・技術・手順(TTP)、セキュリティアラート、脅威インテリジェンスレポート、ツール構成などがこれに該当します。
脅威情報のうち、サイバー攻撃などの脅威を特定した上で、意思決定プロセスに欠かせないコンテキストを与えるために集約、変形、分析、解釈、補強されたものを「脅威インテリジェンス」または「サイバーインテリジェンス」と呼びます。英語で「Threat Intelligence」あるいは「Cyber Threat Intelligence(CTI)」とも表記される脅威インテリジェンスは、差し迫ったリスクからの防御に活用されるほか、中長期的な防御計画の策定に関する意思決定プロセスでも役立ちます。攻撃者が使うマルウェアの情報(ハッシュ値やファイル名)、IPアドレス、ドメインは前者の例として、攻撃者のツールやTTPなどは後者の例に挙げられます。
サイバーインテリジェンスは、特定の脅威に関連した情報や、その脅威に対する防御・検知・対処法といった技術的要素に限定されるものではありません。ネット上から多くの情報を収集・分析して情報の価値を最大化する取り組みであり、事業戦略やセキュリティ対策における意思決定を円滑に行うための「支援的なアウトプット」を意味します。
サイバーインテリジェンスの対象領域は、ダークウェブ上の脅威の監視、さまざまな脅威の分析、トレンド把握、クレジットカードの不正利用対策、エンドポイントセキュリティ、フォレンジック、フィッシングの監視など多岐にわたり、国外ではすでに多くの企業に採用されています。脅威の先手を取ったセキュリティ対策が可能になる、あるいは膨れ上がる一方のセキュリティ予算を最適化できるようになるなど非常に効果が高く、国内でも金融機関や大手製造企業などで導入され、新たなセキュリティ対策として注目を集めるようになりました。

画像1:データ、インフォメーション、インテリジェンスの違い
インテリジェンスサイクルの概要
実効性のあるサイバーインテリジェンスを生産するため、意思決定者の要求に基づいて情報を収集し、生データを分析・処理した上で、目的に即した行動を起こすために必要なインテリジェンスを生産・共有する一連の流れを「インテリジェンスサイクル」と言います。インテリジェンスサイクルは通常、以下の5つのステップから構成され、場合によっては6段階に分けられることもありますが、このサイクルを通じてやるべきことに違いはありません。
- 計画・方向性
- 収集
- 処理
- 分析・生産
- 共有・フィードバック
「サイクル」という名前が示すように、これらのステップを一周したら終わりではなく、共有されたインテリジェンスを基に新たな方向性(要件)が定まり、再び情報を収集して分析・処理・生産・共有を繰り返すことでインテリジェンスが改善され、継続的な運用が可能になります。
効果的なサイバーインテリジェンスプログラムを作成・維持するには、インテリジェンスサイクルとそれぞれのステップをよく理解しておく必要があります。ここからは各ステップについて詳しく見ていきましょう。
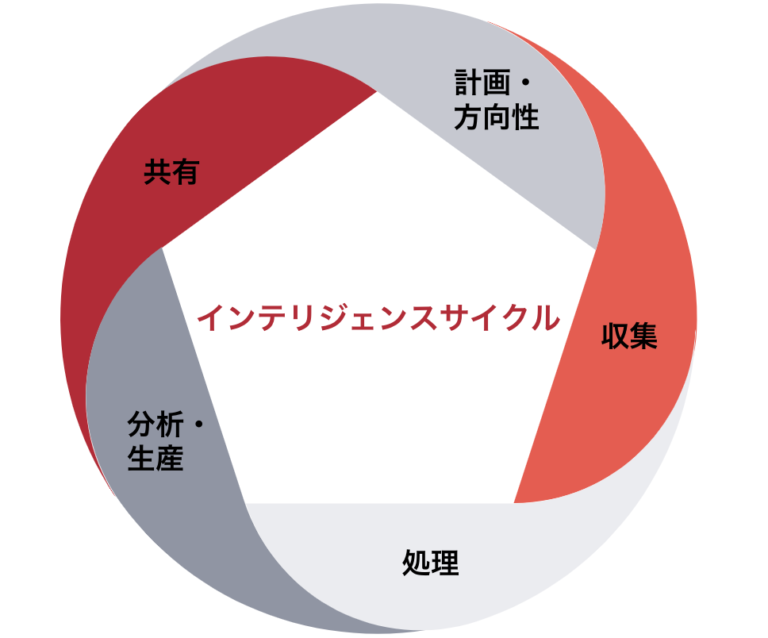
画像2:インテリジェンスサイクルを回し、必要に応じて改善していくことが重要
①計画・方向性
インテリジェンスサイクル全体の出発点となり、その後の全アクションの方向性が決まるために極めて重要なのが「計画・方向性」のステップです。ここでは、インテリジェンス活動を通じて達成したい最終的なゴールやメインのタスクである「インテリジェンス要件」を定義します。この要件定義を行う上では、情報資産の洗い出しと各資産のリスクの特定、組織の脆弱性の把握といったプロセスが必要になります。また、組織のセキュリティニーズのあらゆる側面が考慮されるよう、さまざまなステークホルダー(利害関係者)へのヒアリングを実施することも重要です。
これらの要素を踏まえて定義されたインテリジェンス要件は、その後の全ステップの指針となります。例えばこの後説明するように、要件によってデータの収集源は左右されますし、成果物であるインテリジェンスレポートの書式、配布方法なども変わってきます。また、的確な要件を設定することは、組織にとって真に関連性が高く、実践にも活用可能で組織の戦略的優先事項に合致したインテリジェンスを収集できるようにする上でも欠かせません。逆に言えば、要件定義が不十分な状態でインテリジェンスサイクルを回しても、的外れなソースから情報を収集してしまって自組織と関係性の薄いノイズのような情報が増えてしまったり、対策に活かしづらいデータばかりが集まってしまうといった事態が起こり得るということです。
インテリジェンス要件を踏まえ、実際の実施スケジュールやリソースの配分、データ収集の優先順位づけなど、全体の方向性を決めて計画を立てることもこのステップの実施事項に含まれます。
主な実施内容
- 具体的なインテリジェンス要件の定義
- 重要な資産とシステムの特定
- 収集の優先順位の設定
- タイムラインと期限の設定
- リソース配分の決定
検討すべきポイント
- どのような種類の資産、プロセス、人員がリスクにさらされているのか?
- サイバーインテリジェンスによって、チームの運用効率をどのように向上させるのか?
- ほかにどのようなシステムやアプリケーションが恩恵を受けるのか?
3種類のサイバーインテリジェンス
なお、サイバーインテリジェンスは活用目的に応じ、組織の幹部層が活用することを想定した「戦略インテリジェンス(Strategic Intelligence)」、セキュリティチームのマネージャー向けの「運用インテリジェンス(Operational Intelligence)」、SOC(Security Operation Center)向けの「戦術インテリジェンス(Tactical Intelligence)」の3種類に分類され、それぞれが長期的、長中期的、短期的な防御計画を策定する際の意思決定プロセスに役立ちます(こちらの記事でも詳しく解説しています)。
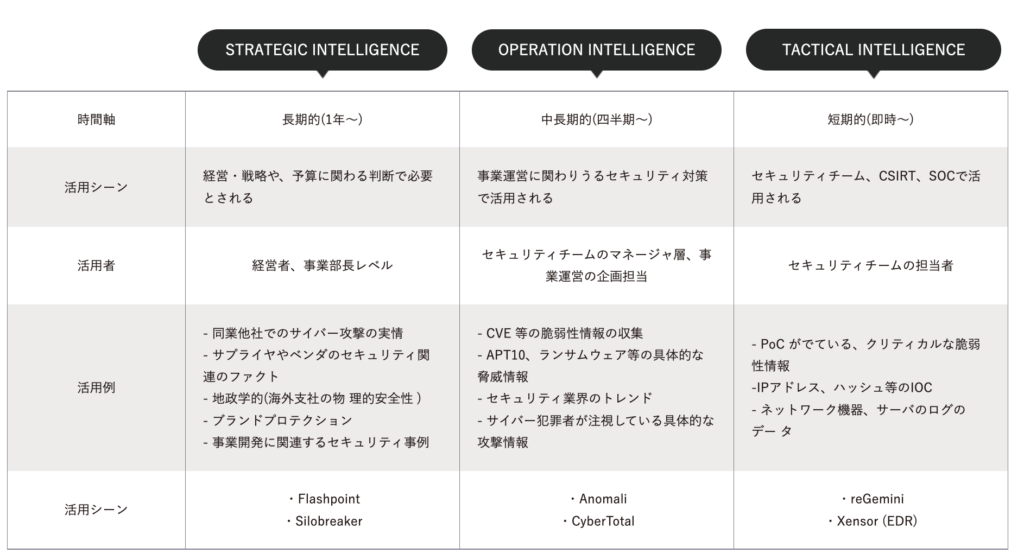
画像3:サイバーインテリジェンスの3分類とその具体例(情報源:弊社ホームページ)
要件定義について
前述の通り、インテリジェンスとは意思決定を円滑に行うための「支援的なアウトプット」です。したがってインテリジェンスにおける要件定義とは、言い換えると「意思決定者が何を求めているのか」を明らかにする作業とも言えます。もう少し具体的には、以下の5点を明確にすることが重要です。
- WHAT:何を知りたいのか?
- WHO:誰が必要としているのか?
- WHY:どうして必要なのか?
- HOW:どんなフォーマットで提供を受けたいか?
- WHEN:いつ、どのくらいの頻度で提供して欲しいのか?
なおこのインテリジェンス要件は、「優先的インテリジェンス要件(Priority Intelligence Requirements:PIR)」と表現されることもあります。PIRは元々軍事および諜報分野で生まれた概念ですが、サイバーセキュリティをはじめとするさまざまな分野に応用・適用されています。
では、PIRには具体的にどのようなものがあるのでしょうか?先ほど触れた3種類のインテリジェンス別にみてみましょう。
戦略インテリジェンスにおけるPIRの例
- 地政学リスク:国際貿易紛争や地政学的不安など、サイバーセキュリティに影響を与え得る地政学的事象や経済的側面を考慮する。
- 法規制:業界固有の規制変更やコンプライアンス要件、およびそれらによって発生し得るリスクを特定する。
- サプライチェーンリスク:供給問題を引き起こす可能性のある地政学的変化を理解する。
運用インテリジェンスにおけるPIRの例
- トレンド把握:新たな攻撃手法や脅威アクターの戦術的進化といったサイバーセキュリティのトレンドを特定・追跡する。
- ダークウェブ上の議論:ダークウェブやアンダーグラウンドフォーラムで自組織に関連する議論を監視し、攻撃計画、機微データの漏洩、システム悪用に関する議論の可能性を特定する。
- 脆弱性の動向:自社で使用する製品が影響を受ける新たな脆弱性やその深刻度などの情報を把握する。
戦術インテリジェンスにおけるPIRの例
- マルウェア情報:マルウェアの挙動、配信メカニズム、IoCなど、特定の業界を標的とするマルウェアキャンペーンの情報を常に把握する。
- インサイダー脅威:組織内の機微なデータやシステムにアクセスできる悪質な意図を持った従業員やサプライヤーがいないかなど、潜在的なインサイダー脅威(内部不正者)についての情報を収集する。
- 喫緊で対応が必要な脆弱性:攻撃での悪用が確認されていたり、PoCエクスプロイトが出回っていたりする重大な脆弱性に関する情報をいち早く収集する。
②収集
このステップでは、「計画・方向性」のステップで決定された要件に基づいて実際にデータを収集します。データの収集源(データソース)や収集すべき情報の種類は要件によって変わり、場合によっては多種多様なソースから大量のデータを集める必要が出てきますが、ツールを用いることで自動化も可能です。
データの量と質はいずれも重要な要素で、どちらかに偏ると誤検知が頻発する、あるいは深刻な脅威イベントを見逃す危険性が高まります。このステップではデータの量と種類の両方の観点から、収集の対象となる情報源の範囲を見極めることが大切です。集めるデータには例えば、自社になりすましているドメインやフィッシングURL、漏洩している認証情報、ネットワークログ、新たな脆弱性(CVE)や悪用されている脆弱性の情報、同業界を狙うマルウェアに関するデータ、脅威アクターによるハッカーフォーラムへの投稿など、幅広い種類の情報が含まれます。
データソースの決定
現代社会にはあまりにも多くの情報が溢れており、これらをただ大量に集めても「インテリジェンス」にはならず、膨大なデータを有効に活用することができません。
サイバーインテリジェンスに用いるデータは、主に以下の4タイプのソースから収集されます。①計画・方向性で決定した目的や要件に応じ、どのソースから情報を収集すべきかを考えることが大切です。
オープンソースデータ
一般に公開され、誰もが自由に利用できるあらゆるデータをオープンソースデータといい、ニュース、ブログ、フィード、ソーシャルメディア、プレスリリース、フォーラム(掲示板)、リポジトリサイトなどがこれに該当します。具体的には、ランサムウェア攻撃や情報漏洩などのインシデントに関するニュース記事、公的機関が公表する注意喚起情報、脅威アクターの手口に関する公開レポート、地政学/国際情勢に関する報道などが有用な情報源として想定されます。なお、インテリジェンスの一分野であるオープンソースインテリジェンス(OSINT)も主にこのグループに属します。
アンダーグラウンドのデータ
ディープウェブまたはダークウェブ上のフォーラム、マーケットプレイス、チャットサービス、ブログなどのデータを指します。特にフォーラムやマーケットプレイスでは、攻撃手法や悪用できそうな脆弱性についてハッカー同士が情報共有していたり、漏洩した認証情報や個人情報、企業情報などが売買されていることがあります。なお、ダークウェブへのアクセスには危険が伴う場合がある上、ダークウェブに存在する情報の量は膨大であり、またこうした情報の選別・監視・分析には専門的なスキルが必要なことから、ダークウェブでの情報収集は専門の企業が提供する有償のダークウェブ調査・監視ツールを使って実施することが推奨されます。
プレミアムデータ
インテリジェンスでの使用を意図して有償で提供されるデータソースを指します。インテリジェンス企業などが作成またはキュレーションしたデータや脅威フィード、脅威リサーチレポートなどがその一例です。
内部データ
自組織のネットワークにおけるユーザーの行動やシステムのアクティビティに関するログ、EDRなどのセキュリティ製品が発出したアラート、IoC関連の情報などが、内部データに相当します。こうした情報は、攻撃の検知や内部不正の発見、インシデントに繋がり得る設定ミスの特定などに役立つことが期待されます。
サイバーインテリジェンスでは通常、こういったソースから集めたデータを使うことになりますが、データの収集と回収に関しては主にベンダーのサービスなどが利用されます。いずれにせよ「データ=インテリジェンス」ではなく、データという原料を精製することでインテリジェンスが抽出されます。
検討すべきポイント
- 現時点で、どこが社内・社外の盲点になっているのか?
- どのような技術を使った自動の収集手法を活用できるのか?
- ダークウェブ上のサイバー犯罪フォーラムやクローズドソースにどの程度潜入できるのか?

③処理
収集されたデータの標準化、構造化、重複排除を行うステップです。生データを構造化された形式に変換して人間(アナリスト)が分析しやすい状態にする作業を指し、「加工」と呼ばれることもあります。このプロセスにはデータのクリーニングと整理、不整合の除去、IPアドレスと既知の攻撃者との関連付けなどのコンテキストの追加が含まれ、ツールを使って自動で行われるのが一般的です。処理の具体例としては、データの量の削減、外国語のダークウェブマーケットプレイス/不法フォーラムから取得した会話の翻訳、マルウェアサンプルからのメタデータ抽出などが挙げられます。
このステップにはデータの検証と品質を保証するための強力なメカニズムが欠かせず、それによって正確で関連性の高い、最新のデータを利用できるようになります。自動化ツールやスクリプトはデータ収集と標準化の効率を上げると共に、手作業による負担やエラーの削減に役立ちます。さらに機械学習や人工知能(AI)といった高度なテクノロジーは、パターンや異常を特定することでデータ処理を改善し、さらなる分析に役立つ知見を提供します。
主な実施内容
- 多様なデータ形式の標準化
- 冗長な情報の重複を排除
- 追加のコンテキストによるエンリッチメント
- 正確性と関連性の検証(あるIPアドレスが複数のインテリジェンスベンダーによって有害なものとして認識されているのか、あるいはそのIPアドレスを発見したブログ以外では有害と認識されていないのかなど)
④分析・生産
収集・処理されたデータを綿密に分析し、想定される活用者の意思決定に繋がる実用的な「インテリジェンス」へと変換するステップです。ここでは、インテリジェンスアナリストが自動化ツールや自らの知識とスキルを使って分析を行い、背景情報(コンテキスト)や既知の情報との相互関連性を踏まえて、想定される影響や今後生じ得る将来のリスクなどについて評価します。
自動化ツールと人間の専門知識を組み合わせることは、効果的な分析を行う上で重要です。ツールは膨大な量のデータを迅速に精査し、重要なパターンを浮かび上がらせることができる一方で、これらのパターンを解釈し、前後の文脈を踏まえて評価するためにはアナリストの存在が欠かせません。特定された脅威の自組織への関連度や重要度を、アナリストが自らの経験と知識を活かして評価することにより、生成されるインテリジェンスは正確かつ実用的なものになります。また、アナリスト同士が協力し合って知見を共有し、調査結果を共同で検証することも、脅威を包括的に把握するために重要です。
実用的なインテリジェンスの作成における4つの重要ポイント
- データの信頼性:データがどれくらい信頼できるものなのか
- データの正当性:データがどれくらい正確で、妥当なものなのか
- データの時宜性:データがどれくらいタイムリーなものなのか
- データの関連性:インテリジェンス要件とどれくらい関連性があるデータなのか、自組織にとってどの程度重要なデータなのか
データ精査時に用いられる手法の例
- 統計分析
- 機械学習アルゴリズム
- 行動分析
- 構造化分析手法(SAT)
など
分析の例
戦略インテリジェンスにおける分析の例
- 分析対象の例:流行中の脅威情報、脅威アクターの動向、他社インシデント事例など
- 分析・評価の例:上記データから読み取れる脅威アクターの攻撃の概要、これまでに観測された攻撃事例や標的となった地域・業界、動機といった脅威情報を分析し、自組織は当該アクターの攻撃対象となり得る資産を有しているのか、自組織が攻撃される可能性はどれくらいあるのか、もし攻撃を受けた場合はどの程度の影響が想定されるのか、どのような対策が必要か、などの項目について評価する。
運用インテリジェンスにおける分析の例
- 分析対象の例:脅威アクターが使用する攻撃手法やツールなど
- 分析・評価の例:MITRE ATT&CK®などのフレームワークを活用し、自組織に対して当該脅威アクターの攻撃が有効かどうか、攻撃を防御または検知することが可能かなどを検証する。
戦術インテリジェンスにおける分析の例
- 分析対象の例:IPアドレス、ファイルハッシュ、URL、ドメインなど(IoC)
- 分析・評価の例:取得したIoC情報を既知の脅威情報と関連付けたり、VirusTotalなどの診断サービス/機能でスキャンしたりすることで、脅威アクター情報や悪性スコアなどの付帯情報を付け加える。これを踏まえ、自組織のセキュリティ製品で侵害を検知することや遮断することは可能か、すでに侵害されてはいないか、などを評価する。
成果物の作成
分析されたデータがまとまったら、これをインテリジェンスレポートやその他の成果物に変換します。フォーマットや書式は各ステークホルダーのニーズに応じて適切なものを選ぶ必要があります。例えば、ITチームやセキュリティチーム向けのレポートには技術的な内容が含められ、専門用語も多用されることが想定されますが、経営幹部向けのレポートではそうした要素を排除した、より簡潔なエグゼクティブサマリーや戦略評価を作成するのが一般的です。
ステークホルダーに合わせたレポートの例
- 経営幹部:戦略的なリスク評価とビジネスへの影響
- セキュリティチーム:技術的な詳細と緩和策
- IT運用チーム:構成ガイダンスとパッチ要件
- コンプライアンスチーム:規制への影響とドキュメント
なお、AIと機械学習が成熟するにつれて、日常的でリスクの低い意思決定など人間主体で行うタスクの一部は自動化が進むと思われます。これによって運用リソースと人員が解放され、より戦略的なタスクや調査を優先できるようになります。
主な実施内容
- 攻撃パターンと傾向を特定
- ビジネスへの潜在的な影響を評価
- 攻撃者の意図と能力を評価
- 攻撃の帰属を特定
- 将来の潜在的な標的を予測
検討すべきポイント
- どのような種類の資産、プロセス、および人員がリスクにさらされているのか?
- 脅威インテリジェンスによって、チームの運用効率をどう向上できるのか?
- ほかにどのようなシステムやアプリケーションが恩恵を受けるのか?
- 分析で最も重要な知見は何か?それを示す最適な方法は何か?
- 分析の信頼性、関連性、正確性はどの程度か?
- 最終的な分析に関して、明確で具体的な推奨事項や次のステップがあるかどうか?
⑤共有・フィードバック
完成したインテリジェンスの成果物を、インテリジェンスの活用者、つまり意思決定者(インテリジェンスの活用者)に配布し、フィードバックを受け取るステップです。先ほど触れたように、活用者によって成果物のフォーマットや書式は異なるほか、配布方式や頻度も変わってきます。
一般的な配布方法としては、Eメールによるレポート配信、ダッシュボードを用いた情報共有、ブリーフィングや会議でのプレゼンテーションなどがあります。タイムリーかつ効果的なコミュニケーションを確保するには、インテリジェンスをいつ、どのように共有すべきかについて明確なガイドラインを確立することが肝心です。
また、フィードバックもこのステップの大切な要素です。完成したインテリジェンスを受け取ったステークホルダーが調査結果を評価し、重要な意思決定を行った上で、事前に定義したインテリジェンス要件とのギャップ分析を行います。これを基にフィードバックを提供することにより、インテリジェンスの運用が継続的に改善されていきます。この作業を繰り返すことでインテリジェンス要件の妥当性が維持され、組織のニーズに適したインテリジェンスを生成できるようになります。
主な実施内容
- 技術チーム、経営陣、取締役など、さまざまなステークホルダーが理解しやすい形式で提示
- セキュリティチームが迅速に対応できるよう、情報を速やかに共有
- インシデント対応計画やセキュリティ情報イベント管理(SIEM)システムなど、既存のセキュリティプロセスやツールに統合
検討すべきポイント
- 完成した脅威インテリジェンスレポートからどのようなステークホルダーが利益を得るのか?
- インテリジェンスを提示する最適な方法、配信頻度は?
- 完成したインテリジェンスはどのような価値を持ち、どれほど実用的なのか、また組織が十分な情報に基づく意思決定を行う上でどう役立つのか?
- 完成したインテリジェンスと組織のインテリジェンスサイクルの両方を改善する点において、今後どのように改良を重ねることができるのか?
インテリジェンスサイクルがなぜ重要なのか
インテリジェンスサイクルの各ステップについて知識が深まったところで、このサイクルがなぜ重要なのかについて改めて考えてみましょう。
インテリジェンスの取り組みを行うための基本指針となる
「サイバーインテリジェンス」というと、ダークウェブの監視ツールやOSINT関連のツールなど、「ツールやソリューション類」のイメージも強いことから、実際にどういったプロセスで取り組めばいいのかがわかりにくい場合があります。しかし、今回説明したようなインテリジェンスサイクルを理解すれば、何をどのような順序で何のために実施すべきなのかが見えてきて、単なるツールの利用に留まらない有意義なインテリジェンスの取り組みを始めることができます。つまりインテリジェンスサイクルは、インテリジェンスの活動を本格的に実施する上で踏むべきステップのガイド役のような役割を果たしてくれるということです。
構造的・体系的なアプローチが可能になる
インテリジェンスサイクルは軍事・諜報分野に端を発し、長年にわたる理論的裏付けと実務的検証を経て体系化されたプロセスです。これをテンプレートとして順々に各ステップをこなしていくことで、構造的かつ体系的にインテリジェンス活動を実施することができます。また、インテリジェンスサイクルはPDCAサイクルを踏まえた継続実施を前提にしたものです。一周して終わりではなく、フィードバックをもとに改善を繰り返すことで、作成できるインテリジェンスの質も上がっていくことが期待できます。
最後に
インテリジェンスサイクルは、組織がインテリジェンス活動を実施する際の基本的な指針となる重要なツールであり、意思決定に役立つ質の高いサイバーインテリジェンスを作成する上で大きな役割を果たします。また、サイバーインテリジェンスの取り組みを体系的に実施する上でも重要な概念であり、全ステップのうち最初の「計画・方向性」はその後の各ステップを左右するため特に肝心です。その一方、データ収集や処理などは自動化することも可能であり、脅威インテリジェンスプラットフォーム(TIP)のようなツールがあるとより効率的にインテリジェンスサイクルをループさせることができます。
インテリジェンスの導入や運用でお困りの場合は、弊社マキナレコードがお手伝いいたします。
マキナレコードはこれまで、サイバーインテリジェンス業界の最先端の海外パートナーと提携し、脅威インテリジェンスツールを始め、インテリジェンス導入のためのトレーニングやコンサルティングを提供して参りました。国内の官公庁様や上場企業様など、多くのお客様にご好評いただいております。
また、マキナレコードではFlashpointの運用をお客様に代わって行う「マネージドインテリジェンスサービス(MIS)」も提供しております。
当社のインテリジェンスサービスについて詳しくはホームページをご覧いただくか、以下のフォームからお問い合わせください。

Writer

nosa翻訳ライター
著者
米国留学後、まず翻訳会社で進行管理・渉外を担当し、その後はパン職人など異業種を経てフリーランスの翻訳家に転身。ヨーロッパのサッカーを中心に、各種スポーツや現代美術、ゲームといった分野で長らく英日翻訳に携わる。2023年夏、サイバーセキュリティをめぐる昨今の状況に危機感を覚え、その実状を幅広い読者に伝えたいという思いでマキナレコードの翻訳チームへ。





